When the acorn that would become the SEO industry started to grow, indexing and ranking at search engines were both based purely on keywords.
The search engine would match keywords in a query to keywords in its index parallel to keywords that appeared on a webpage.
Pages with the highest relevancy score would be ranked in order using one of the three most popular retrieval techniques:
- Boolean Model
- Probabilistic Model
- Vector Space Model
The vector space model became the most relevant for search engines.
I’m going to revisit the basic and somewhat simple explanation of the classic model I used back in the day in this article (because it is still relevant in the search engine mix).
Along the way, we’ll dispel a myth or two – such as the notion of “keyword density” of a webpage. Let’s put that one to bed once and for all.
The keyword: One of the most commonly used words in information science; to marketers – a shrouded mystery
“What’s a keyword?”
You have no idea how many times I heard that question when the SEO industry was emerging. And after I’d given a nutshell of an explanation, the follow-up question would be: “So, what are my keywords, Mike?”
Honestly, it was quite difficult trying to explain to marketers that specific keywords used in a query were what triggered corresponding webpages in search engine results.
And yes, that would almost certainly raise another question: “What’s a query, Mike?”
Today, terms like keyword, query, index, ranking and all the rest are commonplace in the digital marketing lexicon.
However, as an SEO, I believe it’s eminently useful to understand where they’re drawn from and why and how those terms still apply as much now as they did back in the day.
The science of information retrieval (IR) is a subset under the umbrella term “artificial intelligence.” But IR itself is also comprised of several subsets, including that of library and information science.
And that’s our starting point for this second part of my wander down SEO memory lane. (My first, in case you missed it, was: We’ve crawled the web for 32 years: What’s changed?)
This ongoing series of articles is based on what I wrote in a book about SEO 20 years ago, making observations about the state-of-the-art over the years and comparing it to where we are today.
The little old lady in the library
So, having highlighted that there are elements of library science under the Information Retrieval banner, let me relate where they fit into web search.
Seemingly, librarians are mainly identified as little old ladies. It certainly appeared that way when I interviewed several leading scientists in the emerging new field of “web” Information Retrial (IR) all those years ago.
Brian Pinkerton, inventor of WebCrawler, along with Andrei Broder, Vice President Technology and Chief Scientist with Alta Vista, the number one search engine before Google and indeed Craig Silverstein, Director of Technology at Google (and notably, Google employee number one) all described their work in this new field as trying to get a search engine to emulate “the little old lady in the library.”
Libraries are based on the concept of the index card – the original purpose of which was to attempt to organize and classify every known animal, plant, and mineral in the world.
Index cards formed the backbone of the entire library system, indexing vast and varied amounts of information.
Apart from the name of the author, title of the book, subject matter and notable “index terms” (a.k.a., keywords), etc., the index card would also have the location of the book. And therefore, after a while “the little old lady librarian” when you asked her about a particular book, would intuitively be able to point not just to the section of the library, but probably even the shelf the book was on, providing a personalized rapid retrieval method.
However, when I explained the similarity of that type of indexing system at search engines as I did all those years back, I had to add a caveat that’s still important to grasp:
“The largest search engines are index based in a similar manner to that of a library. Having stored a large fraction of the web in massive indices, they then need to quickly return relevant documents against a given keyword or phrase. But the variation of web pages, in terms of composition, quality, and content, is even greater than the scale of the raw data itself. The web as a whole has no unifying structure, with an enormous variant in the style of authoring and content far wider and more complex than in traditional collections of text documents. This makes it almost impossible for a search engine to apply strictly conventional techniques used in libraries, database management systems, and information retrieval.”
Inevitably, what then occurred with keywords and the way we write for the web was the emergence of a new field of communication.
As I explained in the book, HTML could be viewed as a new linguistic genre and should be treated as such in future linguistic studies. There’s much more to a Hypertext document than there is to a “flat text” document. And that gives more of an indication to what a particular web page is about when it is being read by humans as well as the text being analyzed, classified, and categorized through text mining and information extraction by search engines.
Sometimes I still hear SEOs referring to search engines “machine reading” web pages, but that term belongs much more to the relatively recent introduction of “structured data” systems.
As I frequently still have to explain, a human reading a web page and search engines text mining and extracting information “about” a page is not the same thing as humans reading a web page and search engines being” fed” structured data.
The best tangible example I’ve found is to make a comparison between a modern HTML web page with inserted “machine readable” structured data and a modern passport. Take a look at the picture page on your passport and you’ll see one main section with your picture and text for humans to read and a separate section at the bottom of the page, which is created specifically for machine reading by swiping or scanning.
Quintessentially, a modern web page is structured kind of like a modern passport. Interestingly, 20 years ago I referenced the man/machine combination with this little factoid:
“In 1747 the French physician and philosopher Julien Offroy de la Mettrie published one of the most seminal works in the history of ideas. He entitled it L’HOMME MACHINE, which is best translated as “man, a machine.” Often, you will hear the phrase ‘of men and machines’ and this is the root idea of artificial intelligence.”
I emphasized the importance of structured data in my previous article and do hope to write something for you that I believe will be hugely helpful to understand the balance between humans reading and machine reading. I totally simplified it this way back in 2002 to provide a basic rationalization:
- Data: a representation of facts or ideas in a formalized manner, capable of being communicated or manipulated by some process.
- Information: the meaning that a human assigns to data by means of the known conventions used in its representation.
Therefore:
- Data is related to facts and machines.
- Information is related to meaning and humans.
Let’s talk about the characteristics of text for a minute and then I’ll cover how text can be represented as data in something “somewhat misunderstood” (shall we say) in the SEO industry called the vector space model.
The most important keywords in a search engine index vs. the most popular words
Ever heard of Zipf’s Law?
Named after Harvard Linguistic Professor George Kingsley Zipf, it predicts the phenomenon that, as we write, we use familiar words with high frequency.
Zipf said his law is based on the main predictor of human behavior: striving to minimize effort. Therefore, Zipf’s law applies to almost any field involving human production.
This means we also have a constrained relationship between rank and frequency in natural language.
Most large collections of text documents have similar statistical characteristics. Knowing about these statistics is helpful because they influence the effectiveness and efficiency of data structures used to index documents. Many retrieval models rely on them.
There are patterns of occurrences in the way we write – we generally look for the easiest, shortest, least involved, quickest method possible. So, the truth is, we just use the same simple words over and over.
As an example, all those years back, I came across some statistics from an experiment where scientists took a 131MB collection (that was big data back then) of 46,500 newspaper articles (19 million term occurrences).
Here is the data for the top 10 words and how many times they were used within this corpus. You’ll get the point pretty quickly, I think:
Word frequency
the: 1130021
of 547311
to 516635
a 464736
in 390819
and 387703
that 204351
for 199340
is 152483
said 148302
Remember, all the articles included in the corpus were written by professional journalists. But if you look at the top ten most frequently used words, you could hardly make a single sensible sentence out of them.
Because these common words occur so frequently in the English language, search engines will ignore them as “stop words.” If the most popular words we use don’t provide much value to an automated indexing system, which words do?
As already noted, there has been much work in the field of information retrieval (IR) systems. Statistical approaches have been widely applied because of the poor fit of text to data models based on formal logics (e.g., relational databases).
So rather than requiring that users will be able to anticipate the exact words and combinations of words that may appear in documents of interest, statistical IR lets users simply enter a string of words that are likely to appear in a document.
The system then takes into account the frequency of these words in a collection of text, and in individual documents, to determine which words are likely to be the best clues of relevance. A score is computed for each document based on the words it contains and the highest scoring documents are retrieved.
I was fortunate enough to Interview a leading researcher in the field of IR when researching myself for the book back in 2001. At that time, Andrei Broder was Chief Scientist with Alta Vista (currently Distinguished Engineer at Google), and we were discussing the topic of “term vectors” and I asked if he could give me a simple explanation of what they are.
He explained to me how, when “weighting” terms for importance in the index, he may note the occurrence of the word “of” millions of times in the corpus. This is a word which is going to get no “weight” at all, he said. But if he sees something like the word “hemoglobin”, which is a much rarer word in the corpus, then this one will get some weight.
I want to take a quick step back here before I explain how the index is created, and dispel another myth that has lingered over the years. And that’s the one where many people believe that Google (and other search engines) are actually downloading your web pages and storing them on a hard drive.
Nope, not at all. We already have a place to do that, it’s called the world wide web.
Yes, Google maintains a “cached” snapshot of the page for rapid retrieval. But when that page content changes, the next time the page is crawled the cached version changes as well.
That’s why you can never find copies of your old web pages at Google. For that, your only real resource is the Internet Archive (a.k.a., The Wayback Machine).
In fact, when your page is crawled it’s basically dismantled. The text is parsed (extracted) from the document.
Each document is given its own identifier along with details of the location (URL) and the “raw data” is forwarded to the indexer module. The words/terms are saved with the associated document ID in which it appeared.
Here’s a very simple example using two Docs and the text they contain that I created 20 years ago.
Recall index construction

After all the documents have been parsed, the inverted file is sorted by terms:
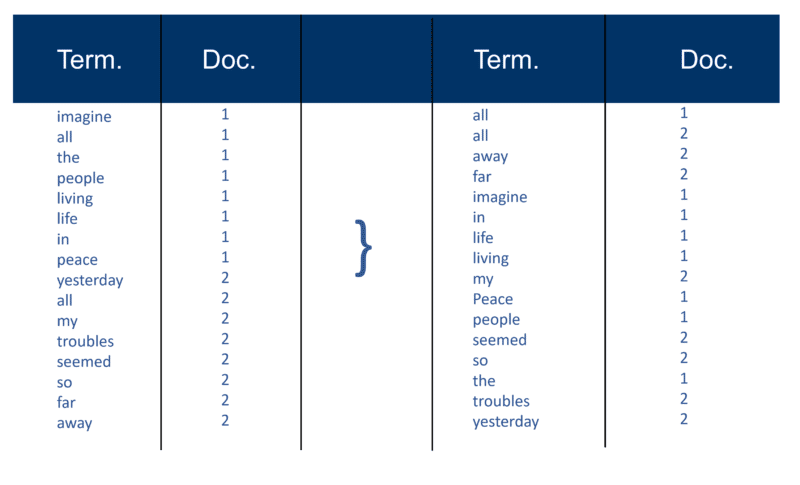
In my example this looks fairly simple at the start of the process, but the postings (as they are known in information retrieval terms) to the index go in one Doc at a time. Again, with millions of Docs, you can imagine the amount of processing power required to turn this into the massive ‘term wise view’ which is simplified above, first by term and then by Doc within each term.
You’ll note my reference to “millions of Docs” from all those years ago. Of course, we’re into billions (even trillions) these days. In my basic explanation of how the index is created, I continued with this:
Each search engine creates its own custom dictionary (or lexicon as it is – remember that many web pages are not written in English), which has to include every new ‘term’ discovered after a crawl (think about the way that, when using a word processor like Microsoft Word, you frequently get the option to add a word to your own custom dictionary, i.e. something which does not occur in the standard English dictionary). Once the search engine has its ‘big’ index, some terms will be more important than others. So, each term deserves its own weight (value). A lot of the weighting factor depends on the term itself. Of course, this is fairly straight forward when you think about it, so more weight is given to a word with more occurrences, but this weight is then increased by the ‘rarity’ of the term across the whole corpus. The indexer can also give more ‘weight’ to words which appear in certain places in the Doc. Words which appeared in the title tag <title> are very important. Words which are in <h1> headline tags or those which are in bold <b> on the page may be more relevant. The words which appear in the anchor text of links on HTML pages, or close to them are certainly viewed as very important. Words that appear in <alt> text tags with images are noted as well as words which appear in meta tags.
Apart from the original text “Modern Information Retrieval” written by the scientist Gerard Salton (regarded as the father of modern information retrieval) I had a number of other resources back in the day who verified the above. Both Brian Pinkerton and Michael Maudlin (inventors of the search engines WebCrawler and Lycos respectively) gave me details on how “the classic Salton approach” was used. And both made me aware of the limitations.
Not only that, Larry Page and Sergey Brin highlighted the very same in the original paper they wrote at the launch of the Google prototype. I’m coming back to this as it’s important in helping to dispel another myth.
But first, here’s how I explained the “classic Salton approach” back in 2002. Be sure to note the reference to “a term weight pair.”
Once the search engine has created its ‘big index’ the indexer module then measures the ‘term frequency’ (tf) of the word in a Doc to get the ‘term density’ and then measures the ‘inverse document frequency’ (idf) which is a calculation of the frequency of terms in a document; the total number of documents; the number of documents which contain the term. With this further calculation, each Doc can now be viewed as a vector of tf x idf values (binary or numeric values corresponding directly or indirectly to the words of the Doc). What you then have is a term weight pair. You could transpose this as: a document has a weighted list of words; a word has a weighted list of documents (a term weight pair).
The Vector Space Model

Now that the Docs are vectors with one component for each term, what has been created is a ‘vector space’ where all the Docs live. But what are the benefits of creating this universe of Docs which all now have this magnitude?
In this way, if Doc ‘d’ (as an example) is a vector then it’s easy to find others like it and also to find vectors near it.
Intuitively, you can then determine that documents, which are close together in vector space, talk about the same things. By doing this a search engine can then create clustering of words or Docs and add various other weighting methods.
However, the main benefit of using term vectors for search engines is that the query engine can regard a query itself as being a very short Doc. In this way, the query becomes a vector in the same vector space and the query engine can measure each Doc’s proximity to it.
The Vector Space Model allows the user to query the search engine for “concepts” rather than a pure “lexical” search. As you can see here, even 20 years ago the notion of concepts and topics as opposed to just keywords was very much in play.
OK, let’s tackle this “keyword density” thing. The word “density” does appear in the explanation of how the vector space model works, but only as it applies to the calculation across the entire corpus of documents – not to a single page. Perhaps it’s that reference that made so many SEOs start using keyword density analyzers on single pages.
I’ve also noticed over the years that many SEOs, who do discover the vector space model, tend to try and apply the classic tf x idf term weighting. But that’s much less likely to work, particularly at Google, as founders Larry Page and Sergey Brin stated in their original paper on how Google works – they emphasize the poor quality of results when applying the classic model alone:
“For example, the standard vector space model tries to return the document that most closely approximates the query, given that both query and document are vectors defined by their word occurrence. On the web, this strategy often returns very short documents that are only the query plus a few words.”
There have been many variants to attempt to get around the ‘rigidity’ of the Vector Space Model. And over the years with advances in artificial intelligence and machine learning, there are many variations to the approach which can calculate the weighting of specific words and documents in the index.
You could spend years trying to figure out what formulae any search engine is using, let alone Google (although you can be sure which one they’re not using as I’ve just pointed out). So, bearing this in mind, it should dispel the myth that trying to manipulate the keyword density of web pages when you create them is a somewhat wasted effort.
Solving the abundance problem
The first generation of search engines relied heavily on on-page factors for ranking.
But the problem you have using purely keyword-based ranking techniques (beyond what I just mentioned about Google from day one) is something known as “the abundance problem” which considers the web growing exponentially every day and the exponential growth in documents containing the same keywords.
And that poses the question on this slide which I’ve been using since 2002:

You can assume that the orchestra conductor, who has been arranging and playing the piece for many years with many orchestras, would be the most authoritative. But working purely on keyword ranking techniques only, it’s just as likely that the music student could be the number one result.
How do you solve that problem?
Well, the answer is hyperlink analysis (a.k.a., backlinks).
In my next installment, I’ll explain how the word “authority” entered the IR and SEO lexicon. And I’ll also explain the original source of what is now referred to as E-A-T and what it’s actually based on.
Until then – be well, stay safe and remember what joy there is in discussing the inner workings of search engines!
The post Indexing and keyword ranking techniques revisited: 20 years later appeared first on Search Engine Land.


